Machine Learning Frameworks Interoperability
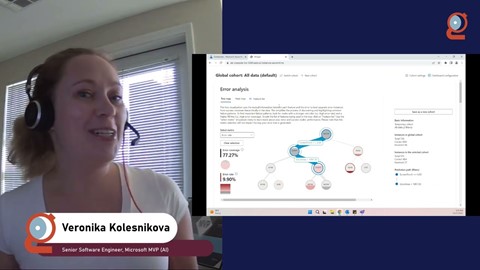
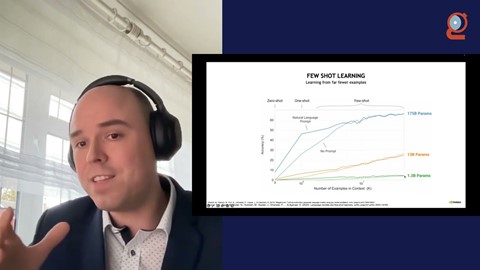
To develop mature data science, machine learning, and deep learning applications, one must develop a large number of pipeline components, such as data loading, feature extraction, and frequently a multitude of machine learning models. The complexity of those components frequently requires use of a broad range of software components/tools, creating challenges during pipeline integration. We'll discuss zero-copy functionality across several GPU-accelerated and non-GPU-accelerated data science frameworks including, among others, PyTorch, TensorFlow, Pandas, SciKit Learn, RAPIDS, CuPy, Numba, and Jax. Zero-copy avoids unnecessary data transfers, hence drastically reducing execution time of your application. We'll also address memory layouts of the associated data objects in various frameworks, the efficient conversion of data objects using zero-copy, as well as using a joint memory pool when mixing frameworks.